6 min read
La Data Virtualization
In tutti i mercati verticali, le organizzazioni adottano la virtualizzazione dei dati come parte fondamentale della propria infrastruttura IT perché i dati stanno diventando più distribuiti, più eterogenei e di volume maggiore. Le pressioni sulle imprese affinché diventino più competitive sono in continua crescita, quindi è più importante che mai oggi ottenere un rapido accesso ai dati rilevanti.
I tradizionali approcci legati al concetto di "Logical Data Warehouse" non sono più sufficienti ad esprimere il potenziali dei dati: è un po' come un acquario, ma c'è un mondo più grande che aspetta al di fuori di esso, vi è un' ampia varietà di acquari.
E' giunto il momento di fare quel primo salto in un mondo più vasto, attraverso l'uso delle soluzioni di virtualizzazione dei dati.
L'architettura logica si è evoluta
Mark Bayer di Gartner ha inventato il termine data warehouse logico 10 anni fa per descrivere la necessità di espandere logicamente le architetture esistenti di data warehouse che avrebbero dovuto includere tutte le informazioni aziendali ma non lo facevano. Da allora, termini come "data warehouse logico" e "architetture ibride" sono stati ampiamente utilizzati per rappresentare la naturale evoluzione dei sistemi analitici e la virtualizzazione dei dati ha svolto un ruolo importante in questo processo.
In tempi più recenti, Rick F. van der Lans ha illustrato nel suo post "Unificazione del data warehouse, del data lake e del marketplace dei dati", che la virtualizzazione dei dati può agire come una "piattaforma unificata di consegna dei dati" che riunisce non solo il data warehouse ma anche i data lake, dati dal web, streaming di dati e qualsiasi altro sistema di consegna dei dati, contribuendo a ridurre i silos di dati per supportare una gamma più ampia di casi d'uso.
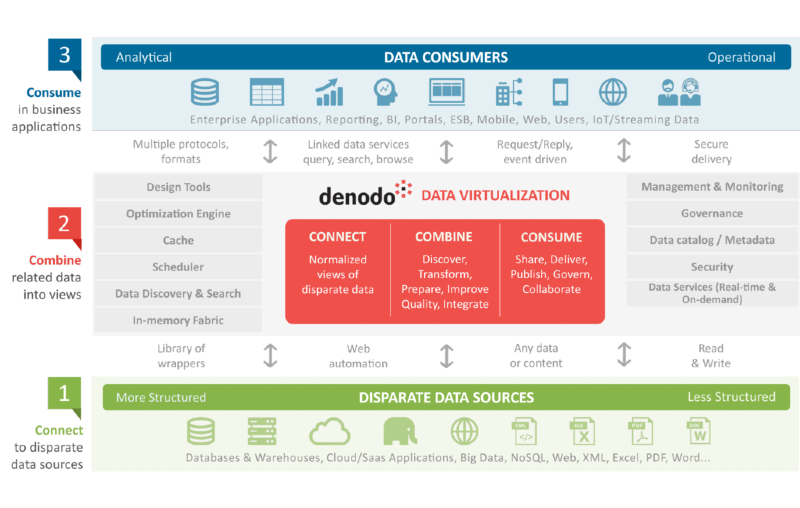
Se consideriamo le capacità della virtualizzazione dei dati delineate nel diagramma, risulta evidente come la virtualizzazione dei dati possa costituire una parte importante della piattaforma di consegna dei dati unificata descritta da Rick.
![[object Object]](http://images.ctfassets.net/o53nxjrshrvi/313j9WRAXglxvr89XWAhJL/d3a95ac52cdad1e6363e78110fd48a9e/Data-Virtualization-A-Unified-Data-Delivery-Platform-for-the-Business.png)
Gli aspetti chiave della virtualizzazione dei dati sono la sua capacità di astrarre la posizione e la loro struttura, fornendo una maggiore velocità di consegna (poiché non devono essere replicati) e consentire agli utenti di consumarli sia in modalità self-service attraverso la consultazione di un catalogo dei modelli logici pubblicati, sia utilizzando tecnologie familiari come SQL o REST per accederli: i dati comunque rimangono sempre in situ, ed è il livello di virtualizzazione che si fa carico di gestire le richieste.
Questa astrazione allenta l'accoppiamento tra IT e business, consentendo agli stakeholder IT di lavorare al proprio ritmo per il provisioning dei dati utilizzando la piattaforma di elaborazione più appropriata, mentre ai consumatori viene fornito l'accesso ai dati ovunque risiedano attraverso il livello logico. Ciò rimuove i silos e consente ai consumatori di accedere ai dati utilizzando le applicazioni di loro scelta, siano essi strumenti di reportistica, strumenti di data science, applicazioni aziendali, o app mobili o web.
Pensa diversamente: 3 architetture, una piattaforma di consegna
La virtualizzazione dei dati costituisce quindi la struttura portante di una piattaforma unificata di consegna dei dati, supportando a pieno titolo l'obiettivo di estrarne valore.
Tra le tante possibili, si descrivono a seguire tre possibili architetture in cui la virtualizzazione dei dati può svolgere un ruolo chiave
Data Service Layers
In questo scenario, la virtualizzazione dei dati pubblica servizi di dati certificati che possono essere utilizzati da qualsiasi team di sviluppo, evitando i problemi dei team di progetto che creano i propri insiemi di dati nascosti, o utilizzano fonti di dati non certificate o non gestite. Con un Data Service Layers, non esiste un accesso diretto alle origini dati. Set di dati coerenti vengono pubblicati e resi rilevabili mediante l'uso della virtualizzazione dei dati, che consente a tutti gli sviluppatori, non solo i team BI, ma anche sviluppatori di applicazioni operative, portali Web, sistemi di back office o front office, di accedere e riutilizzare i dati.
Accelera la Cloud Modernization
Una seconda area è la modernizzazione del cloud. Il percorso per le aziende che desiderano modernizzare le proprie infrastrutture adottando applicazioni cloud e migrando applicazioni legacy nel cloud, richiede tempo e i dati possono diventare ancora più frammentati durante questo processo:
si sviluppano architetture ibride, con alcuni dati ancora in locale ed altri migrati nel cloud;
nascono architetture multi-cloud, che portano alla necessità dell'integrazione delle applicazioni tra i fornitori di piattaforme cloud;
mantenere un unico punto di accesso e sicurezza attraverso l'architettura ibrida dei dati è una necessità imprescindibile .
Le capacità di astrazione della virtualizzazione dei dati abilita l'adozione del cloud: la virtualizzazione dei dati facilita la migrazione dell'architettura legacy nel cloud, aprendo alla possibilità di utilizzare nuove e più evolute piattaforme di analisi dei dati in cloud, garantendo nel contempo la facilità di accesso ai dati in architetture ibride.
Facilita l'adozione dei Big Data
L'ultima area presa in esame è come la virtualizzazione dei dati può aiutare le organizzazioni nell'adozione dei Big Data, consentendo agli utilizzatori di sfruttare con molta più facilità i dati residenti in tali piattaforme:
la virtualizzazione dei dati rende disponibili i big data agli utenti senza competenze sui big data tramite i Logical Data Lake, ovvero il provisioning di un modello logico di facile accesso e scoperta;
la virtualizzazione dei dati consente l'offload di dati storici da costose infrastrutture di data warehouse a storage meno costoso, ad es. Hadoop, consentendo al contempo l'accesso continuo ai dati attuali e storici;
la virtualizzazione dei dati consente la combinazione di big data con altri dati per arricchirli, ad esempio combinando l'output di analisi predittiva con dati aziendali contestuali;
la virtualizzazione dei dati supporta le iniziative di data science consentendo ai data scientist di concentrarsi sull'analisi piuttosto che sull'integrazione dei dati e sull'acquisizione dei dati di cui hanno bisogno.
Un esempio interessante
Un esempio interessante dell'uso della virtualizzazione dei dati nell'analisi predittiva viene da un produttore globale di macchine movimento terra. Questa società voleva differenziare i suoi prodotti riducendo il costo totale di proprietà per i clienti garantendo che funzionassero con efficienza ottimale con tempi di fermo minimi sul campo. Nel processo, la società è stata in grado di fornire un servizio clienti migliore.
La società dispone di sensori su tutte le sue apparecchiature, che inviano i dati da raccogliere in tempo reale a un cluster Hadoop. Gli algoritmi di analisi predittiva vengono eseguiti su tutti i dati del sensore in Hadoop, con l'obiettivo di prevedere quando una parte deve essere sostituita prima del guasto, in modo da poter eseguire la manutenzione preventiva. Questi dati da soli hanno scarso valore attuabile, ma se arricchiti utilizzando la virtualizzazione dei dati con informazioni contestuali da altri sistemi (inventario delle parti, manutenzione, sistemi di concessionaria ecc.), Le analisi aggiungono un reale valore commerciale. Questi dati arricchiti, pubblicati attraverso un portale, consentono all'azienda di offrire un servizio a valore aggiunto ai clienti, consentendo loro di pianificare la manutenzione del proprio impianto al momento giusto per mantenere la produzione in funzione, massimizzando i tempi di attività dell'impianto e riducendo il costo totale complessivo di proprietà.